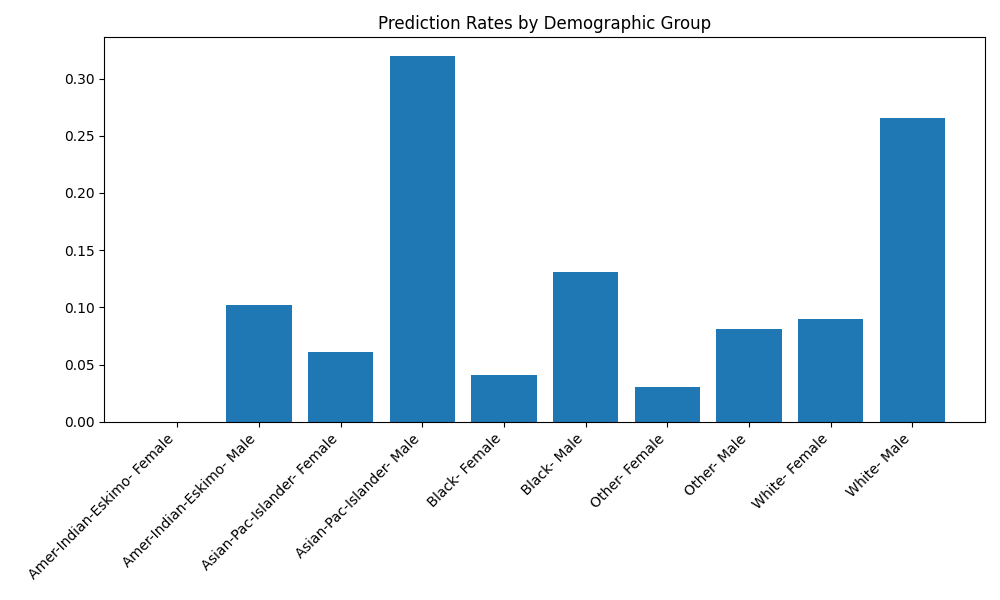
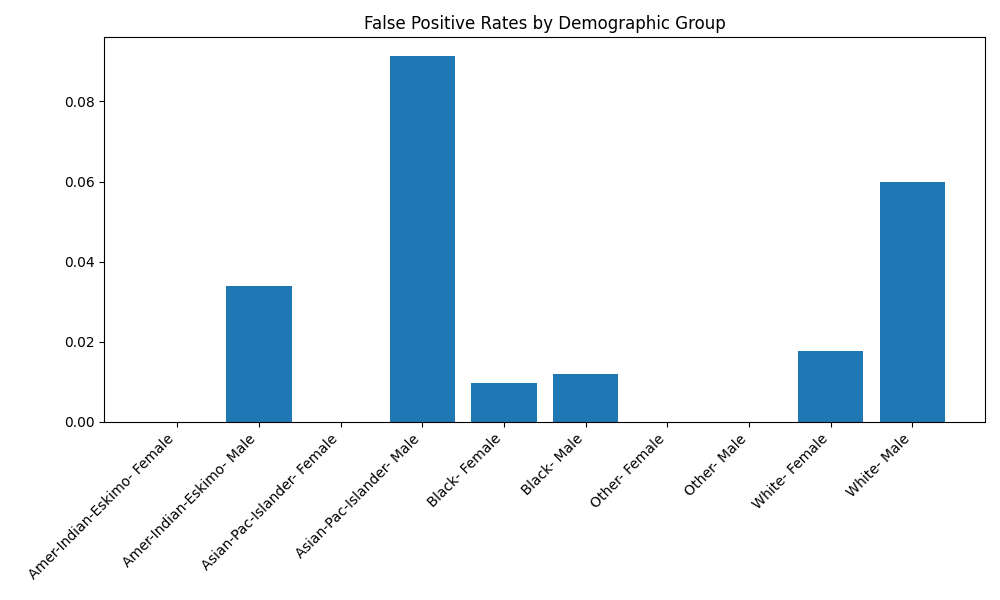
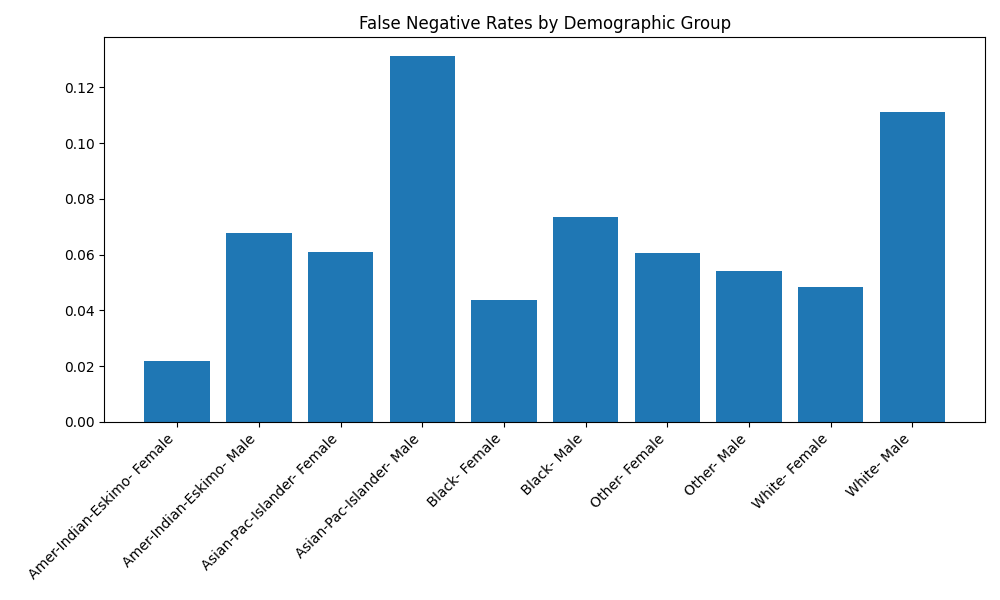
In 2018 I trained a machine learning model to predict whether someone would likely donate to a charity called CharityML. The model scored 86.78% accuracy. I submitted the project, got my grade, and moved on.
What I didn't know: the dataset I used. the UCI Adult Income dataset from the 1994 US Census. had already appeared in hundreds of research papers on AI fairness, privacy preservation, and model debugging, according to UC Berkeley researchers writing in 2021.
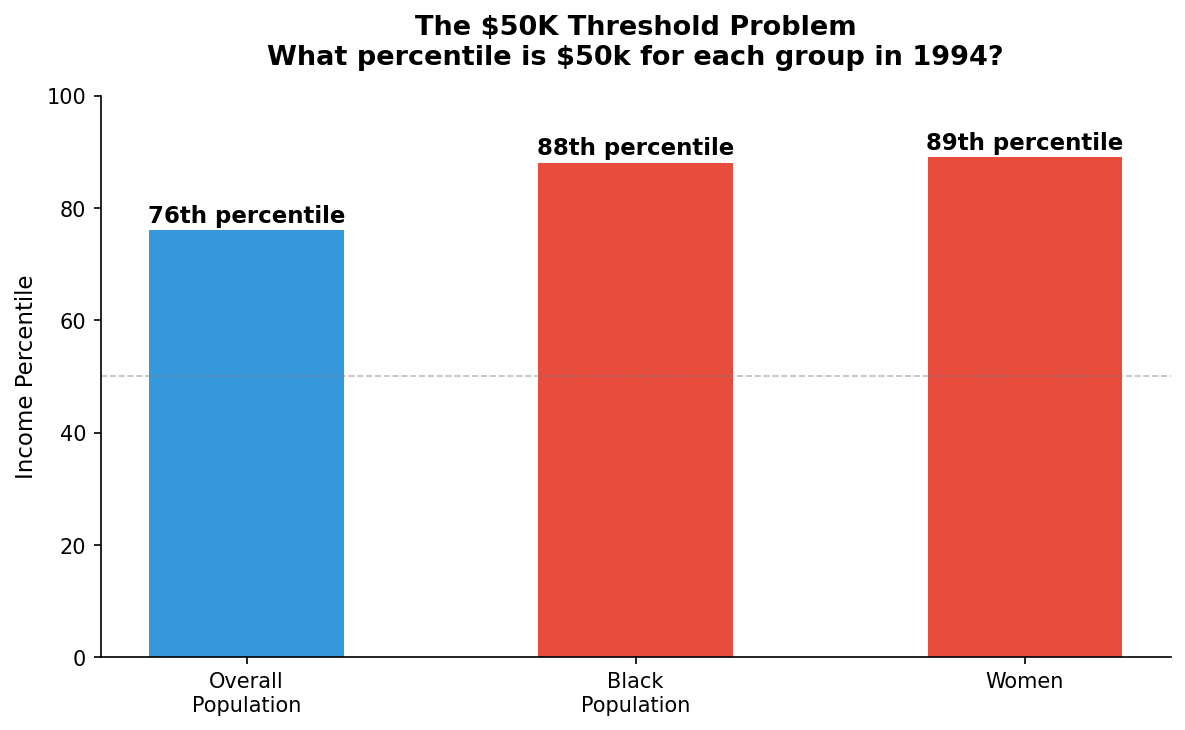
In 2021 UC Berkeley researchers published "Retiring Adult". a paper calling for this dataset to be retired, revealing that the $50k income threshold was the 76th percentile overall, but the 88th percentile for Black Americans and 89th percentile for women. The model didn't learn who donates. It learned who 1994 America paid well.
GitHub Copilot helped me find the deprecated code, modernize the implementation, and audit the fairness of the predictions. Here's what we found.